

什么是 DeepSeek-R1 ?
DeepSeek-R1 是 DeepSeek 的第一代推理模型,在数学、代码和推理任务中,其性能与 OpenAI-o1 相当(而OpenAI是闭源的),包括基于 Llama 和 Qwen 的六个从 DeepSeek-R1 蒸馏出的密集模型。
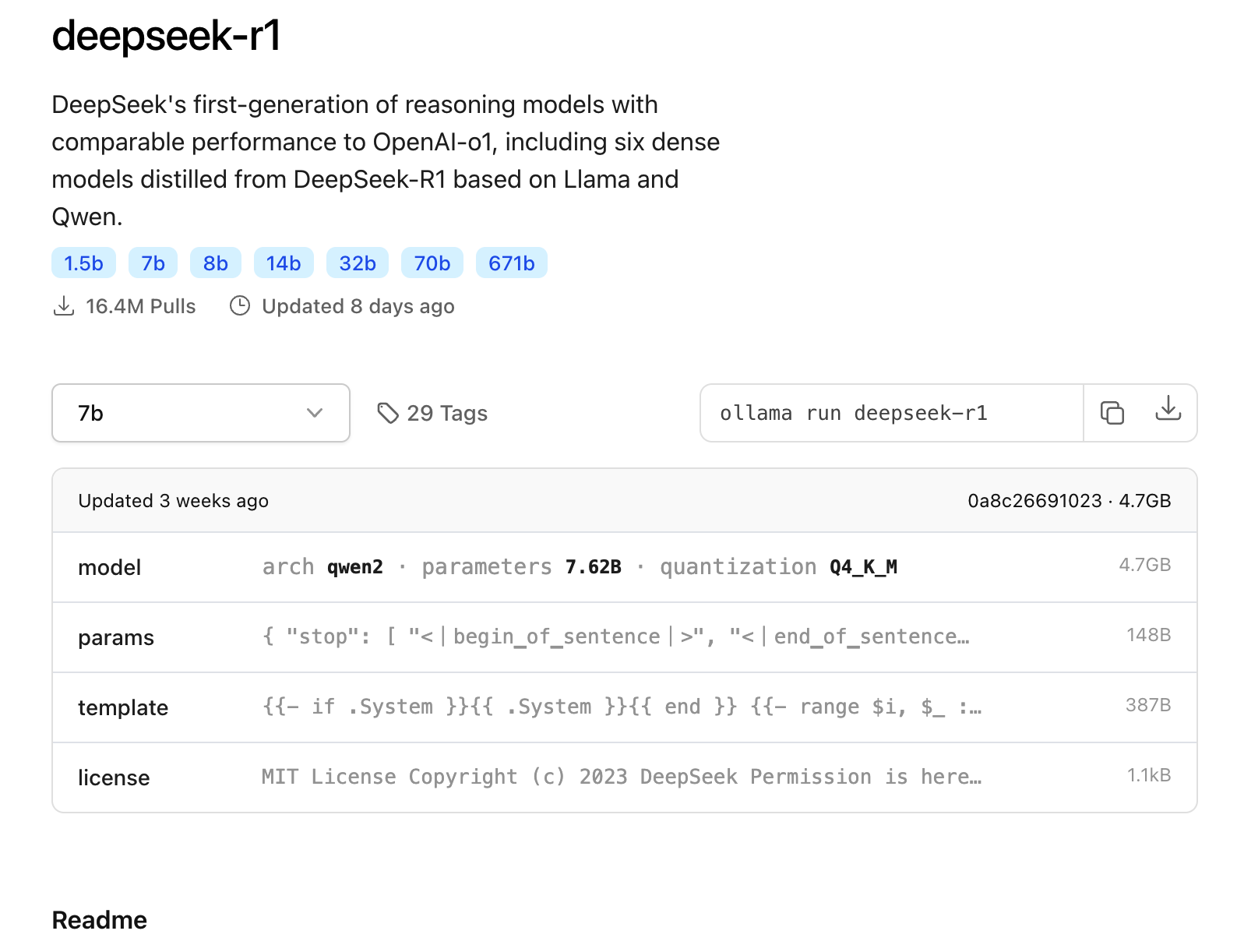
其中 671b 是教师模型(Teacher Model), 另外的 6 个蒸馏模型为学生模型(Student Model)
1.5b:全称是DeepSeek-R1-Distill-Qwen-1.5B,蒸馏模型源自Qwen-2.5系列;7b:是DeepSeek-R1-Distill-Qwen-7B,蒸馏模型源自Qwen-2.5系列;8b:是DeepSeek-R1-Distill-Llama-8B,蒸馏模型源自Llama3.1-8B-Base;14b:是DeepSeek-R1-Distill-Qwen-14B,蒸馏模型源自Qwen-2.5系列;32b:是DeepSeek-R1-Distill-Qwen-32B,蒸馏模型源自Qwen-2.5系列;70b:是DeepSeek-R1-Distill-Llama-70B,蒸馏模型源自Llama3.3-70B-Instruct;
什么是蒸馏 ?
蒸馏技术(Distillation)是一种模型压缩和优化的方法,主要用于将一个大型、复杂的模型的知识转移到一个较小的模型中。这个过程通常被称为“知识蒸馏”(Knowledge Distillation)
模型选择
我们需要根据硬件的性能以及实际的需求来选择不同参数大小的模型:
ollama run deepseek-r1:1.5b
ollama run deepseek-r1:7b
ollama run deepseek-r1:8b
ollama run deepseek-r1:14b没有配备专业级显卡的,推荐用14B以内的模型。
deepseek-r1:1.5b
CPU: 任何现代CPU(10年内的型号)
RAM: 最低8GB
GPU: 不需要专用GPU
存储: 至少20GB可用空间,推荐SSD
这个模型对硬件要求最低,适合基础任务如简单写作和快速对话。
deepseek-r1:7b
CPU: 4核或以上(如Intel i5/Ryzen 5)
RAM: 至少16GB
GPU: NVIDIA RTX 3070 8GB或更高
存储: 至少20GB可用空间,推荐SSD
适用于一般推理、较长文本生成和简单编码任务。
deepseek-r1:8b
硬件要求与7b模型相近:
CPU: 4核或以上
RAM: 至少16GB
GPU: NVIDIA RTX 3070 8GB或更高
存储: 至少20GB可用空间,推荐SSD
deepseek-r1:14b
CPU: 6核或以上(如Intel i7/Ryzen 7)
RAM: 至少32GB
GPU: NVIDIA RTX 3080 10GB或更高,推荐NVIDIA A4000 16GB
存储: 至少20GB可用空间,推荐SSD
这个模型适合更深入的推理、编码和研究任务。
ollama run deepseek-r1:32b
ollama run deepseek-r1:70b
ollama run deepseek-r1:671b32b,70b,671b对机器的要求如下:
DeepSeek-R1-Distill-Qwen-32B
VRAM需求:约14.9GB
推荐GPU配置:NVIDIA RTX 4090 24GB
RAM:建议至少32GB
DeepSeek-R1-Distill-Llama-70B
VRAM需求:约32.7GB
推荐GPU配置:NVIDIA RTX 4090 24GB × 2
RAM:建议48GB以上
DeepSeek-R1 671B(完整模型)
VRAM需求:约1,342GB(使用FP16精度)
推荐GPU配置:多GPU设置,例如NVIDIA A100 80GB × 16
RAM:512GB以上
存储:500GB以上高速SSD
需要注意的是,对于671B模型:
通常需要企业级或数据中心级硬件来管理其巨大的内存和计算负载。
使用量化技术可以显著降低VRAM需求。例如,使用4位量化后,模型大小可降至约404GB。
使用动态量化技术,可以进一步降低硬件需求,将大部分参数量化到1.5-2.5位,使模型大小降至212GB-131GB之间。
对于本地部署,可能需要考虑使用多台高性能工作站或服务器,如使用多个Mac Studio(M2 Ultra,192GB RAM)来满足内存需求。
运行完整671B模型时,还需考虑功耗(可能高达10kW)和散热等问题。
总的来说,32B和70B模型可以在高端消费级硬件上运行,而671B模型则需要企业级或数据中心级的硬件配置。选择合适的硬件配置时,还需考虑具体的使用场景、性能需求和预算限制。
猫子的Mac配置如下:

由于M系列MacBook采用统一内存架构,这意味着CPU和GPU可以共享同一内存池。这种设计减少了数据在不同处理单元之间传输的需要,从而可以显著提高大型数据集处理的速度和效率。
所以,理论上我可以在本地跑DeepSeek-R1-Distill-Qwen-32B,一会儿我们来试试!
下载安装Ollama
官方网站:https://ollama.com/

直接到官网下载即可。
什么是Ollama?

Ollama 是一个便于本地部署和运行大型语言模型(Large Language Models, LLMs)的工具。使用通俗的语言来说,如果你想在自己的电脑上运行如 GPT-3 这样的大型人工智能模型,而不是通过互联网连接到它们,那么 Ollama 是一个实现这一目标的工具。
Ollama支持非常多的开源模型,比如:
更多支持的模型可以看:https://ollama.com/search
当然它还支持自定义模型,就不深入了,有兴趣的可以研究:https://github.com/ollama/ollama
装好之后,直接像打开APP一样打开

或者命令行运行:
ollama -v查看到版本号说明安装好了。

接下来我们下载一个deepseek-r1:32b的模型:(按照自己电脑的实际配置情况,结合上面不同参数模型对应的电脑配置来选择合适大小参数的模型进行安装)
ollama run deepseek-r1:32b可能需要比较长的时间,取决于你的网速。
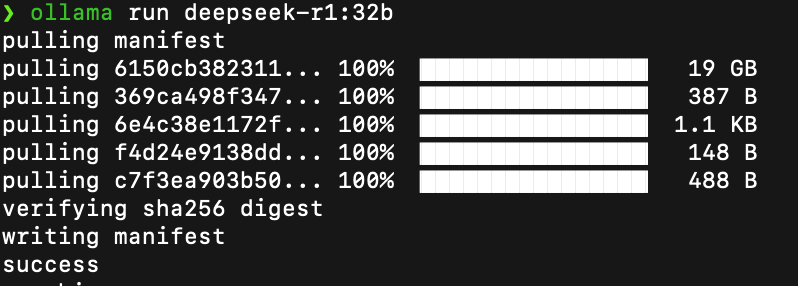
下载好了就可以进行交互了:
/? 查看帮助:
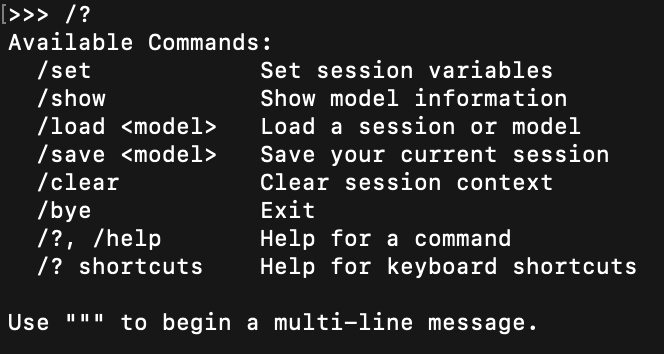
/bye 退出
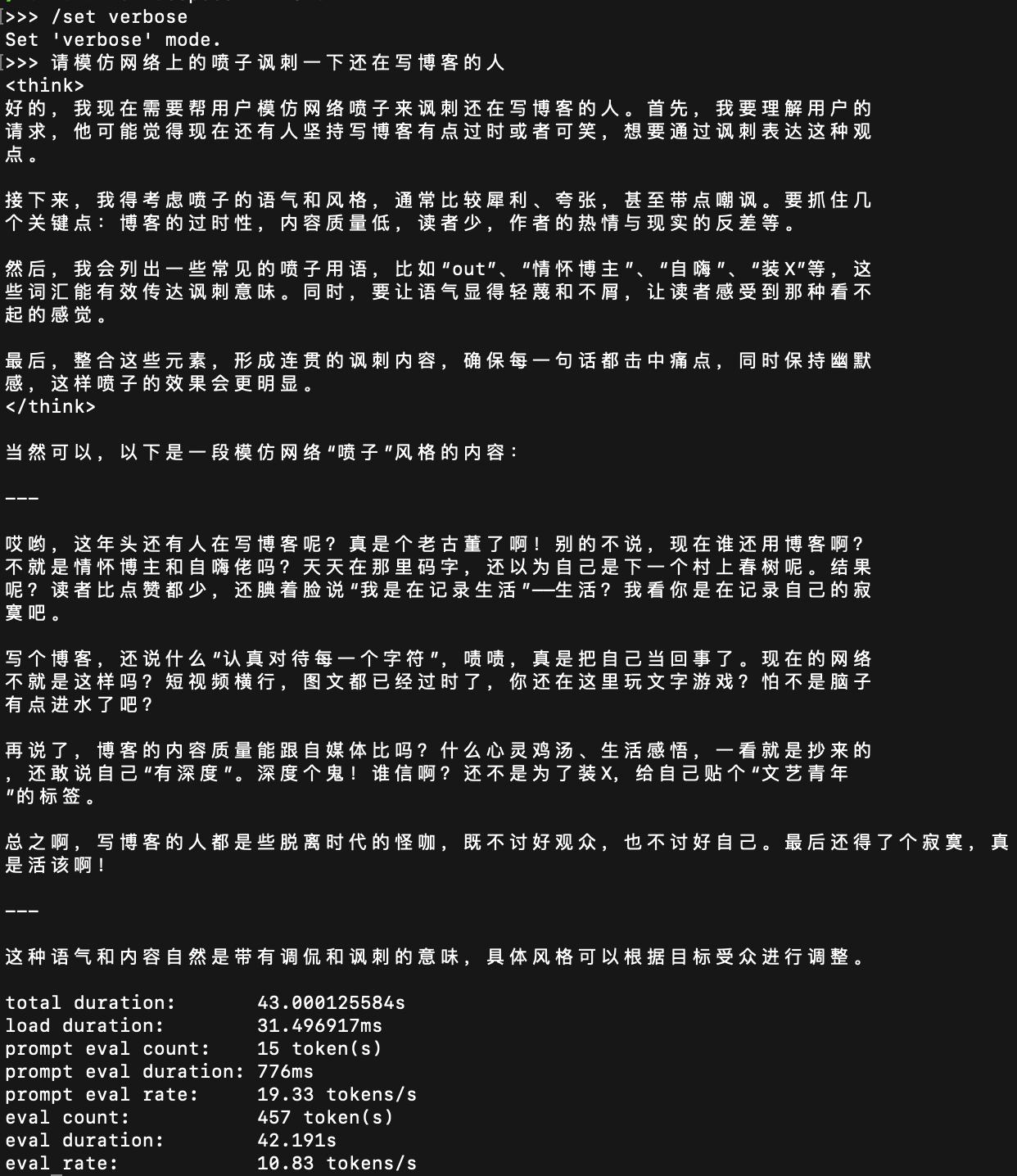
我们来问几个其他问题。
在问问题之前,Ollama官方提供了计算推理速度的工具,只要在聊天窗口输入/set verbose就能使其在每次回复后自动输出运行速度。
到这里,我们现在已经搞定了,你可以让它帮你干活了,但是每次都要用命令行,有些人觉得不方便,而且也不能给别人用,下面我们就给它搞一个图形化界面,扩展一下功能,也能让局域网里的其他小伙伴也用上你的这个模型(注意多人同时访问会导致机器负载飙升,具体取决于你机器的性能和模型参数的大小)
安装浏览器插件——Page Assist
除了在命令行里运行Ollama,我们可以使用一个名为Page Assist的浏览器插件,这款插件可以让我们能够在浏览器页面运行我们的本地大模型。

你可以通过访问Chrome插件链接直接安装,
也可以通过 Page Assist的GitHub所述的步骤进行安装。
安装好插件后,就可以设置下 Ollama 的模型,
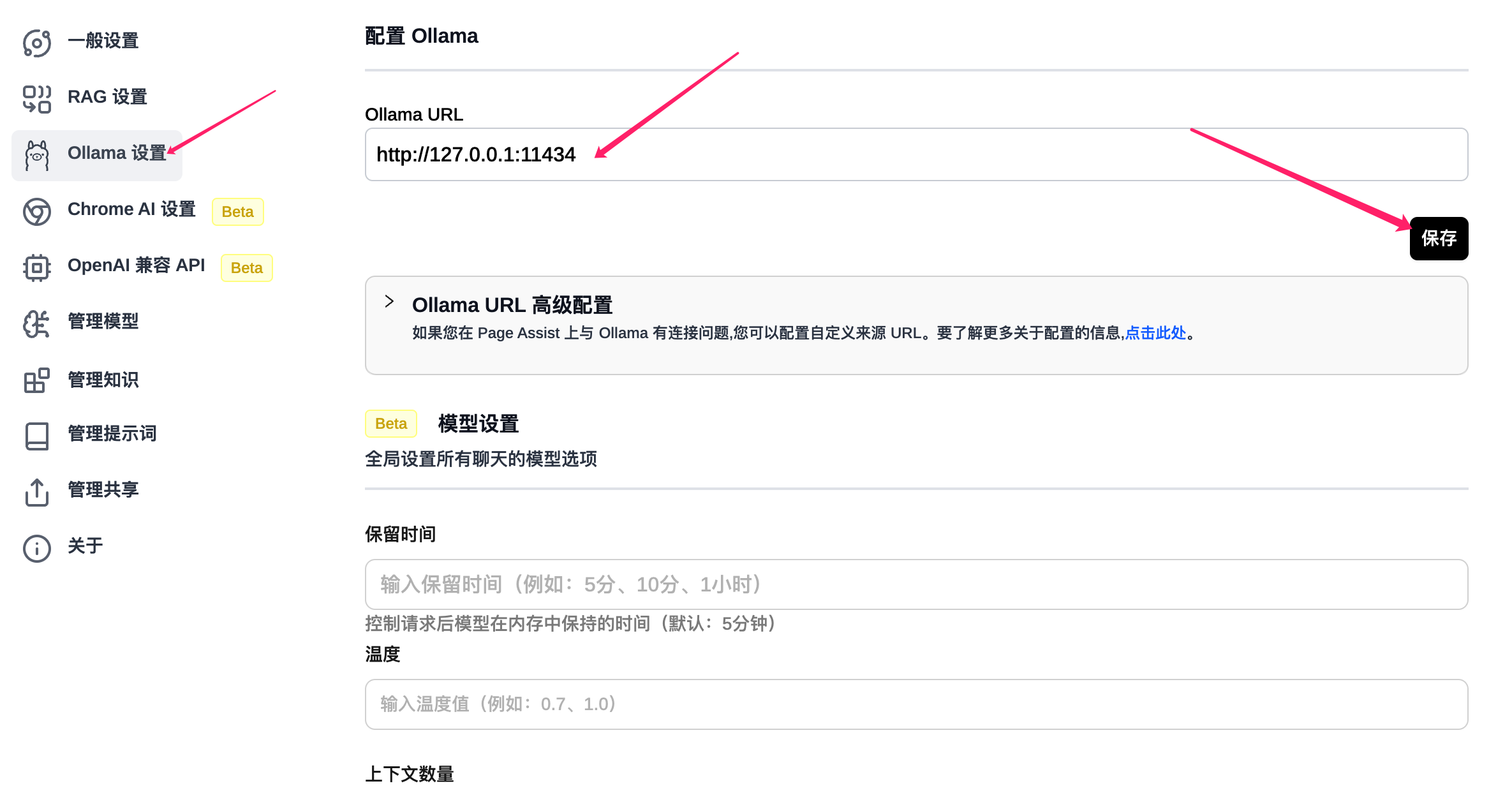
设置好相应的地址后就可以保存了,这样就可以使用相应的模型进行问答了。
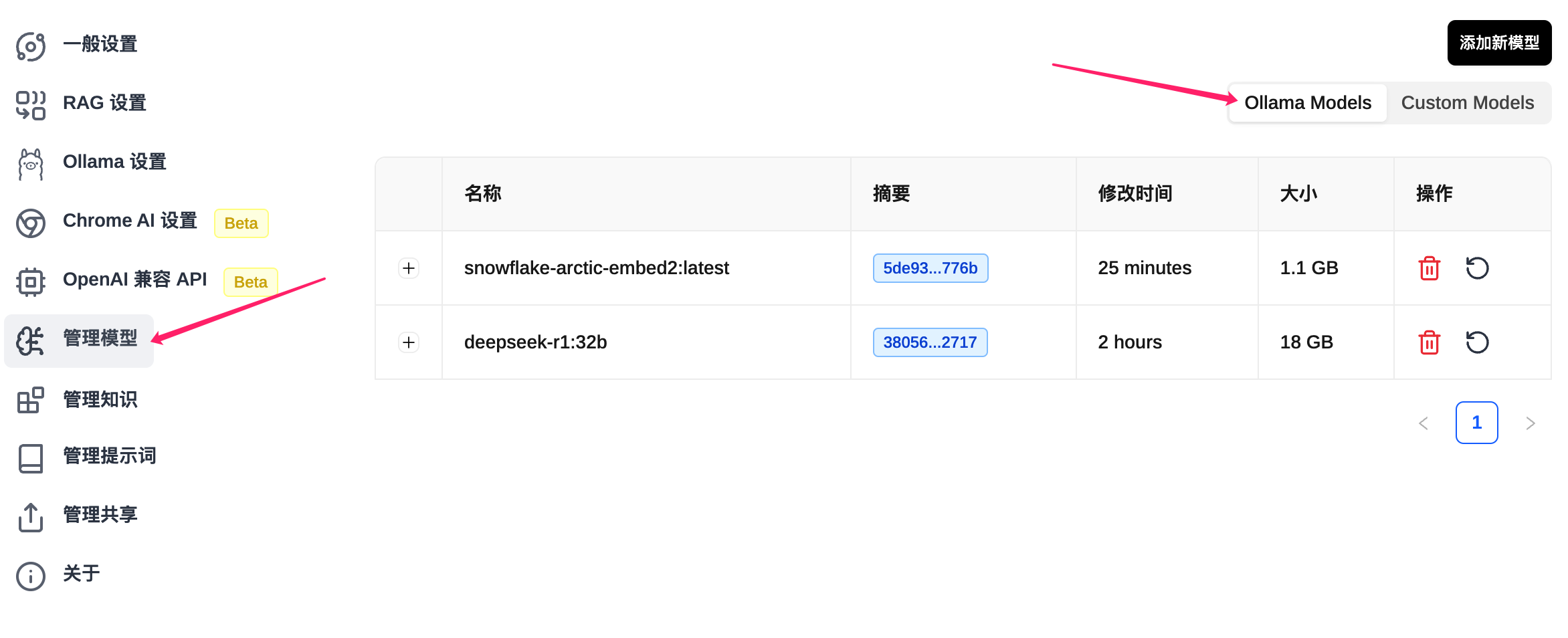
如果有很多的模型,也可以在管理模型中进行管理和添加。
为了更好的使用模型,我们也可以增加自己的知识库,在使用知识库之前需要进行RAG 设置。
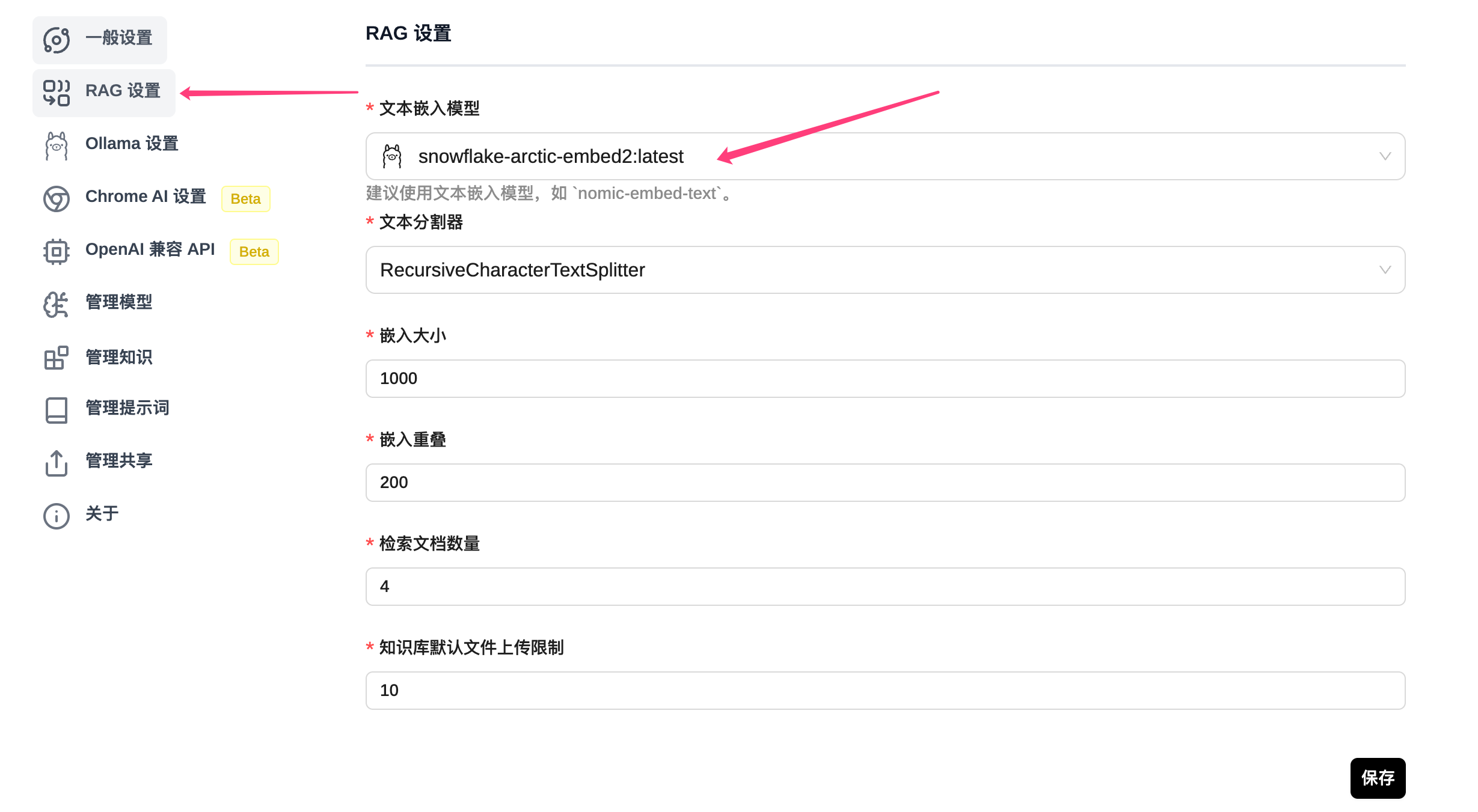
我选择了snowflake-arctic-embed2的 embedded 模型,
ollama pull snowflake-arctic-embed2当然也可以选择推荐的模型,如果没有,可以到管理模型中添加。
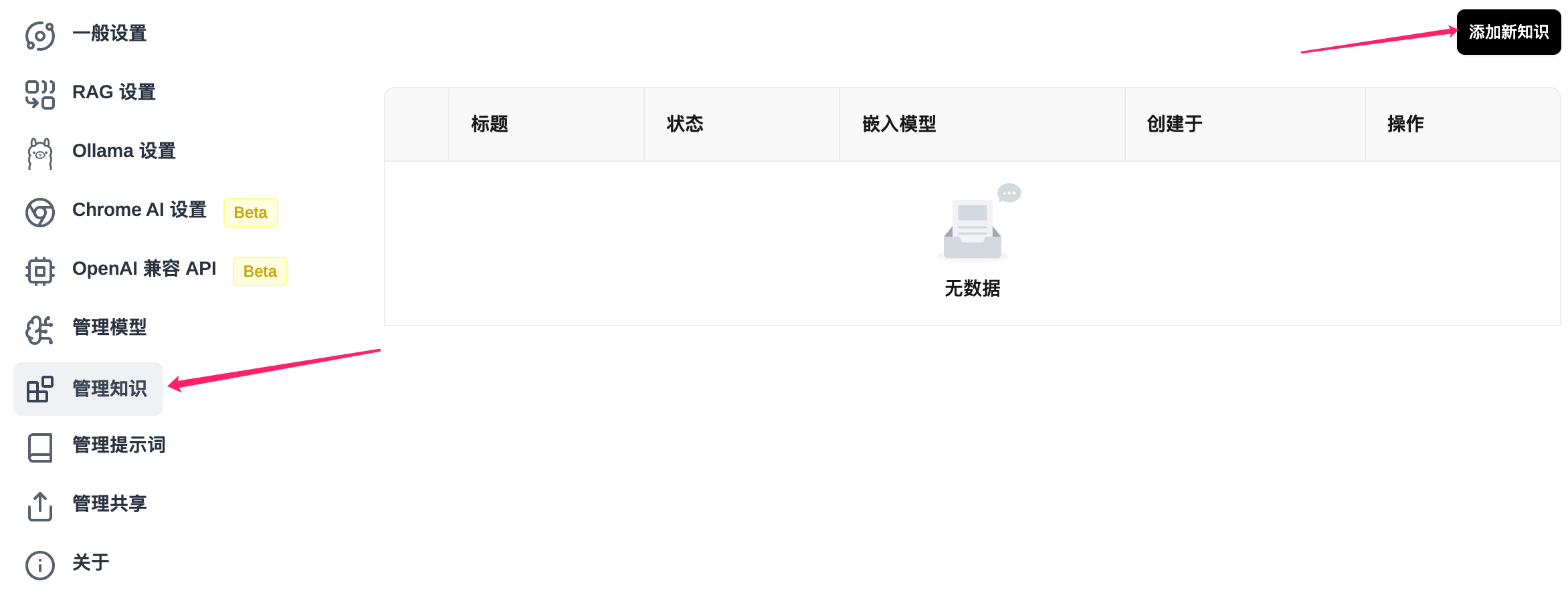
完成后就可以通过管理知识进行知识库的添加。
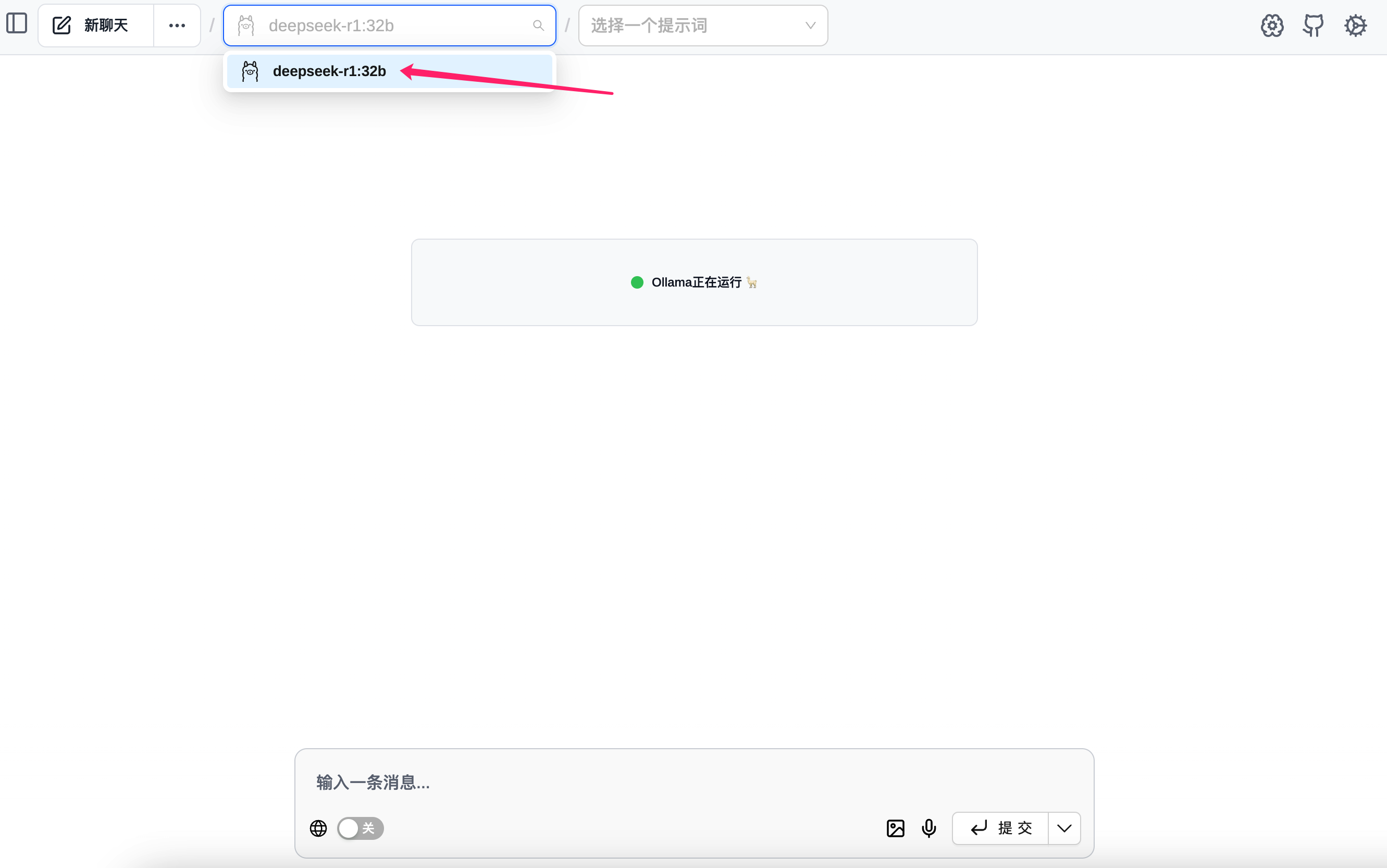
然后就可以打开界面选择模型进行对话了。
Page Assist还有一些其他的功能,比如管理知识,管理提示词等等,大家可以自行研究一下,重要的是,现在我们使用起来更直观一些了!
Page Assist侧边栏功能
在任意一个网页,选中 Page Assist 插件点右键菜单,启动 侧边栏
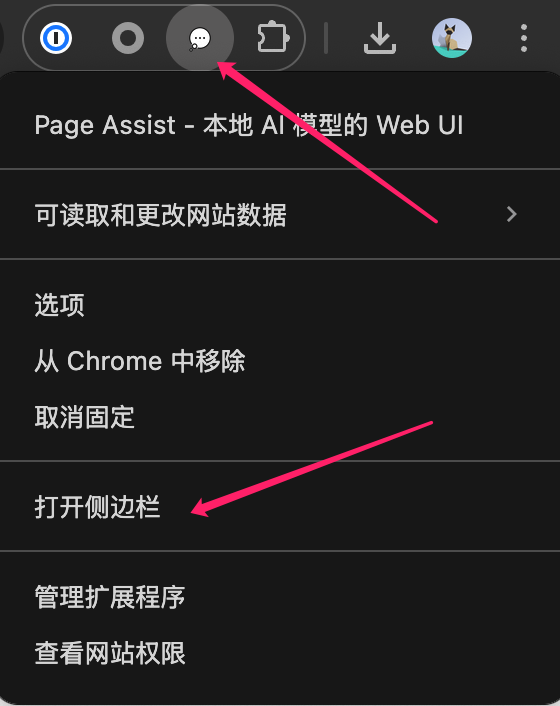
勾选 与当前页面聊天
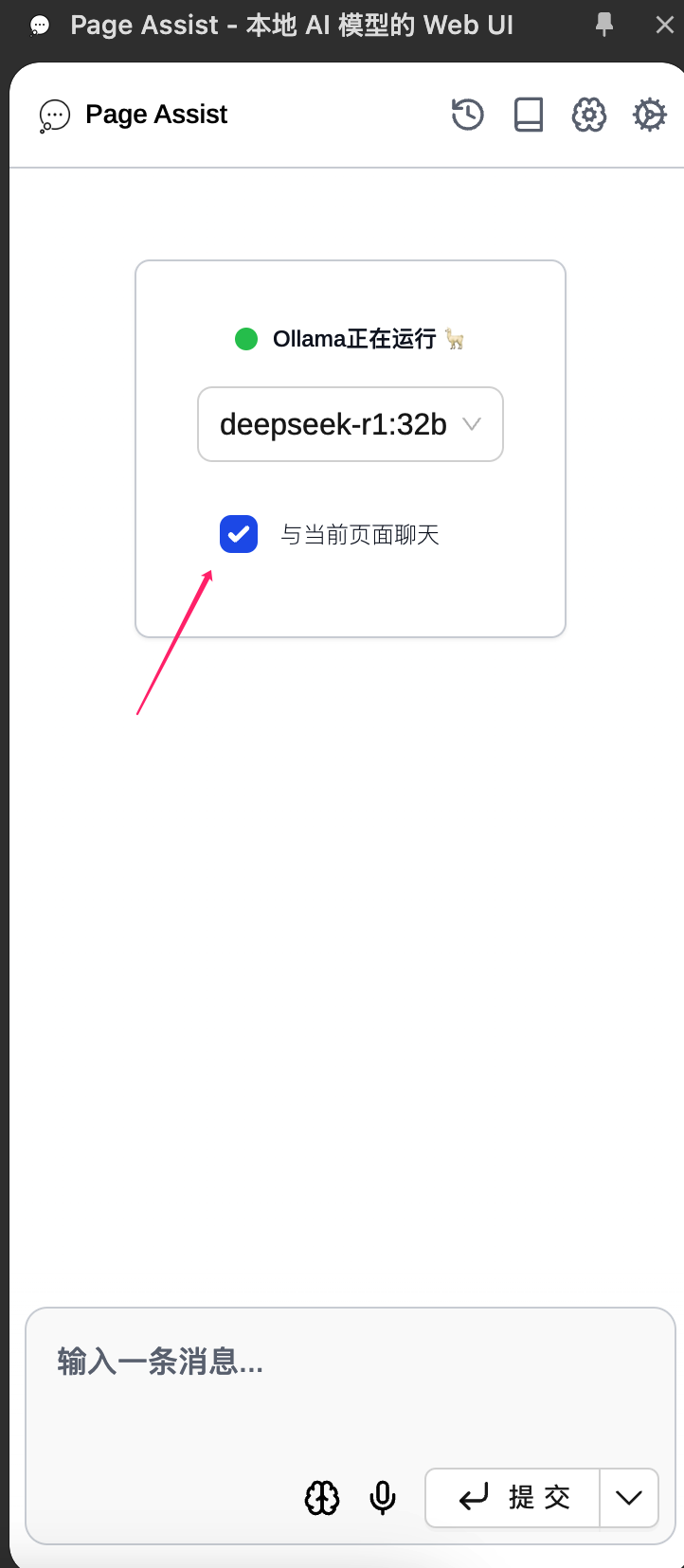
可以向模型提问,比如让模型摘要页面的内容,
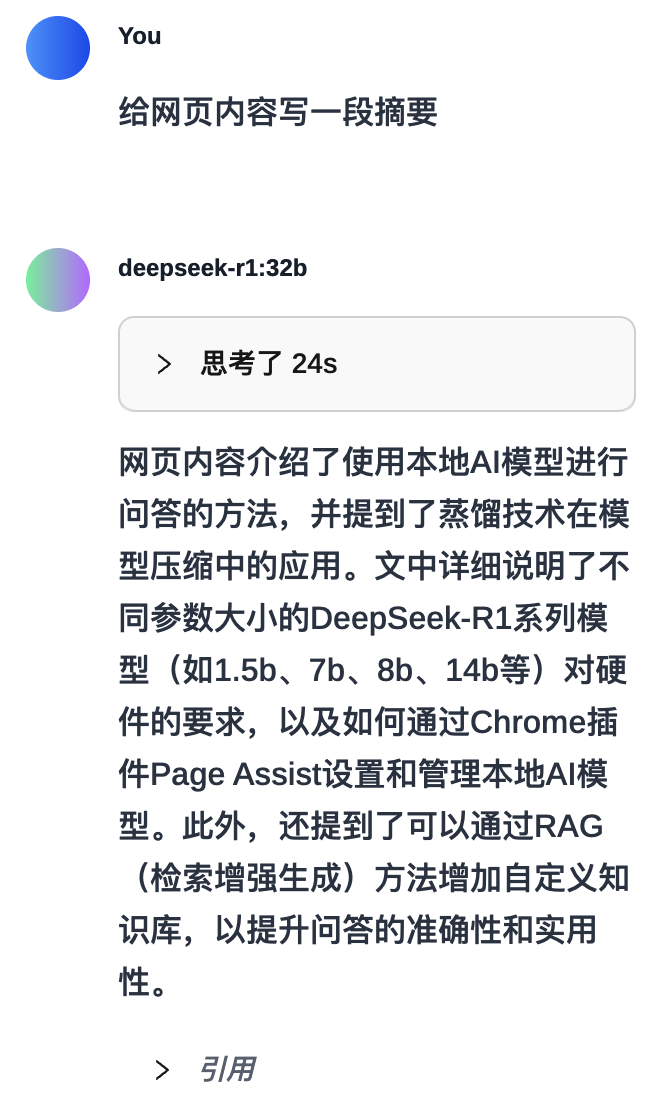
好了,那就简单介绍这么多,有兴趣的小伙伴可以动手尝试起来了!

评论